7.3 Data Analysis by Humans
The recordings were divided into two sets, a development set and a test set. Recordings were first examined by a graduate student in Speech-Language Pathology to identify where syllabic babbles occurred. They were then digitized into the Waves program and edited to remove mothers' utterances, non-speech utterances (e.g., coughs, sneezes, and crying) and background noise. Syllabic utterances were hand-marked using a broad phonetic transcription.In order to remove parents' utterances, non-speech utterances, and background noise from the tapes of the babies we recorded, the tapes were screened to mark the locations and phonetic content of the reduplicative babbles. We digitized only those sections containing clear babbling, omitting sections obscured by extraneous noise or voices. The resulting files were high-pass filtered to remove noise below 150Hz. All files contained recordings of syllables that consisted of, at minimum, a vowel nucleus (a vocant), and optionally, an oral or glottal constriction (a closant).
7.4 Hand-marking Conventions
Two phoneticians (LF, KC) trained together on a set of recordings that contained a representative variety of closants and vocants, working out a system of hand-marking and establishing the following conventions:- Mark closants at the beginning of F0 or at the burst if there was one (i.e., at oral release) with the symbol 'h#'. However, if intervocalic glottal closures are perceptually long enough to function as a syllable boundary between vocants, count them as closants and mark them accordingly with 'h#'. Otherwise, include them with the vocant and do not specifically mark them. /h/ and glottal stops are generally not considered closants. For stops with unclear, fricative-like releases, mark them as closely as possible to the beginning of the release of the constriction, not at the end of frication. For true fricatives, mark both the beginning of frication and the oral release with the symbol 'sh' to delineate the extent of frication.
- Use the symbol 'em' to delineate nasals, marking both oral closure and oral release.
- Use the symbol 'hv' to delineate vocants, marking the beginning and ending of audible F0 energy. Long vowels and diphthongs, even if they contain a change in pitch or amplitude, are considered as one vocant.
- Ignore squeals, utterances with no F0 and bilabial trills (raspberries). To indicate regions in files that should be ignored, delineate them with the symbol 'ax-h'. Also bracket with this symbol nonlinguistic noises and utterances obscured by noise that was not removed by filtering.
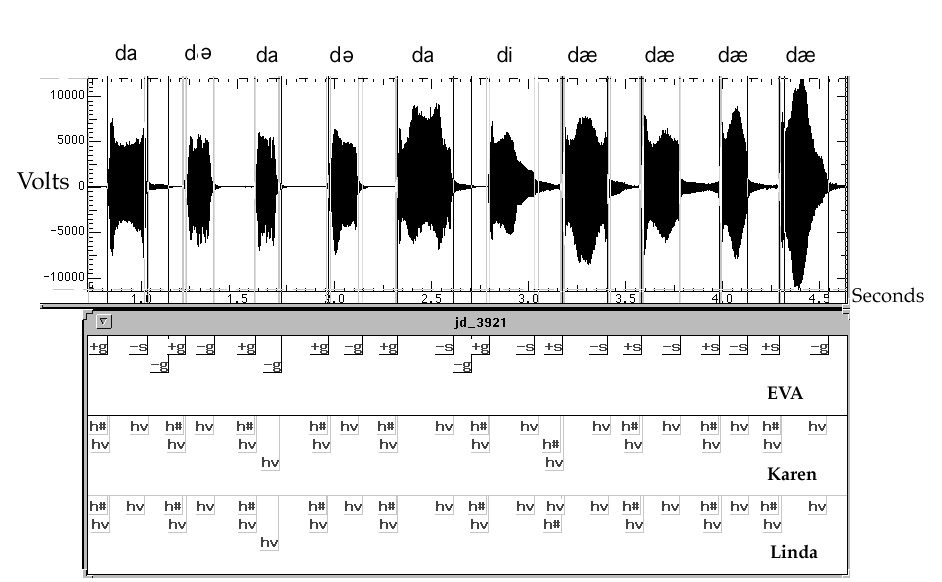
Figure 1: Sample Marking of Landmarks by Human Judges and EVA
7.5 Computer Marking of Landmarks
As described above, Liu's program marks three kinds of landmark, g(lottis), s(onorant), and b(urst) We presently make use only of the glottis and sonorant detectors. Our sonorant-consonant detection algorithm appears to work well on infant vocalization. (Interestingly, Liu's adult version showed high error rates for sonorant-consonants but not for bursts; but we find the reverse.) Between the glottis and sonorant features, we are able to mark voiced syllables. Preliminary results are discussed below while experimentation and analysis continue.
7.6 Experimental Results and Analysis
We performed an inter-judge reliability study and compared EVA to human judgment.7.6.1 Inter-Judge Reliability
The criterion for inter-judge agreement on perceptual hand-marking of landmarks was set at 95%. We defined inter-judge reliability as
( number landmarks agreed upon by both / number agreements + number disagreements)
Inter-judge reliability on the existence, type and placement of landmarks was carried out by having the two trained phoneticians independently mark 15 arbitrarily selected, digitized samples not in the training set. These samples ranged in length from 3 to 10 seconds. Each judge used headphones to listen to the infant utterances, and viewed both the time waveform and wide-band spectrogram on-screen. The judges worked independently, entering their judgments into separate files. At no point did they refer to analyses carried out by the EVA program.
Since the longest file was 10 seconds long, the worst screen resolution was approximately 10 ms per pixel. (Waveforms were typically scaled to the screen width.) The accuracy was limited primarily by screen resolution and each judge's ability to manipulate the computer's mouse.
Between them the two judges marked a total of 204 landmarks (see Figure 1 for an example). The judges marked 198 landmarks that were close to each other. One judge marked 4 landmarks that the second judge did not, and the second judge marked two that the first did not. The two judges agreed on presence and position, to within 50ms, on 185 of the 204 landmarks (91%) and on position, to within 100ms, on 194 of the 204 landmarks (95%). We felt that this agreement met our original training criterion of 95% inter-judge reliability on perceptual hand-marking of landmarks. All utterances marked after the completion of this test were then analyzed by one judge. Problematic utterances were marked and agreement jointly negotiated with the other judge.
7.6.2 EVA to human judge comparison:
To test EVA-human reliability, the following rules were used to match EVA's landmark vocabulary with that of the human judges. Landmarks that were further than 200ms apart were assumed to represent different events.
For the purposes of the first test, we considered as valid only those landmarks hand-marked and agreed upon to within 100ms by both human judges. As shown in the table, we did not count h# (glottal closure) marks at the start of voiced regions because these are not (yet) in EVA's repertoire.
Human Judges | EVA |
| h# (at voicing start) hv hv | (do not match/count) +g -g |
| or | |
| h# (within voicing) hv hv | +s (no correspondence) -g or -s (if both marked, use -g, do not count -s) |
| hv (no preceding h#) hv | +g -g) |
| em (only one instance) em hv hv | +g (no correspondence) -s -g |
| em em (no hv/hv following) | +g -g |
| ay (initial glide) | (ignore region at this point) |
| sh (only one instance) hv hv | +s (no correspondence) -g |
Table 3: Correspondence of EVA and Human Markings
In this test, we considered the human consensus as the standard. H denotes the total number of validly hand-marked landmarks. We counted three kinds of errors for EVA: A deletion is a missed landmark where EVA detected no landmark in the vicinity of the hand-labeled landmark. The deletion rate is given by:
An insertion is a false landmark, i.e., one which was detected by EVA but not by the judges. The insertion rate is given by:
A shift is a landmark, found by EVA and matched by our correspondence rules, that is more than 100ms from the corresponding hand-labeled landmark. The shift rate is given by:
Then the total error rate is defined as:
7.6.3 First Comparison Experiment
As a preliminary test of EVA's agreement with human landmark detection, we ran EVA on 15 digitized samples that were marked by both judges. Together, the 15 digitized samples had 128 validly marked landmarks (agreed on by both judges). Comparatively, EVA had 9 insertions and 3 deletions. Of the 125 landmarks found by EVA that corresponded to the valid human landmarks, only 1 was more than 100ms from either judge. The error rates were:
- Deletion rate = (3/128) x 100% = 2%
- Insertion rate = (9/128) x 100% = 7%
- Shift rate = (1/128) x 100% = 1%
- Total Error rate = 2.3 + 7.0 + 0.8 = 10%
The insertions were a +s/ -s pair 12 ms apart, three +g/ -g pairs 32, 35, and 37ms apart, and an unmatched -g. The deletions were all at the end of one digitized sample and just after a region that was not counted due to disagreement between the judges.
The table below shows the statistics on the 124 landmarks, that were agreed on by both judges and corresponded to EVA landmarks (within 100ms):
Distance | EVA to | >EVA to judge 2 | inter-judge |
| Average | 15.4ms | 13.7ms | 15.0ms |
| Standard Deviation | 16.1ms | 16.3ms | 16.3ms |
| Maximum | 93 | 93 | 90 |
| number > 50ms | 5 | 6 | 6 |
| percent > 50ms | 4.0% | 4.8% | 4.8% |
| number > 70ms | 4 | 4 | 2 |
| percent > 70ms | 3.2% | 3.2% | 1.6% |
Table 4: EVA vs. Human Comparison 1
EVA counted 67 syllables in these samples while the judges found 64. In places where one syllable boundary was missing, 0.5 syllable was counted. EVA deleted 1.5 syllables found by the judges and inserted 4 syllables, the +s/-s and +g/-g pairs described above.
7.6.4 Second Comparison Experiment
Second Comparison Experiment: In this test, the digitized samples were hand-labeled by only one phonetician and compared to EVA's performance. (Based on the previous two-judge comparison, perhaps 2-3% of the differences should be attributed to the judges, not to EVA.) The 11 samples were all of subject LS, five recorded at 7 months and six recorded at 8 months. The phonetician picked these samples to test EVA because they contained relatively few phonemes not yet in EVA's repertoire, e.g. glides. The 7-month samples, however, were known to contain substantial amounts of vocal fry in the utterances, which might interfere with EVA's evaluation.
In the 11 digitized samples, 150 landmarks were marked by the human judge. EVA detected 2 landmarks that the judge did not and omitted 17 that the judge noted. Of the remaining 135 landmarks found by EVA that paired with the valid human landmarks, only 2 were more than 100ms from their corresponding marks. The rates of disagreement (which may or may not be EVA errors) were:
- Omission rate = (19/150) x 100% = 11.3 %
- Extra-detection rate = (2/150) x 100% = 1.3 %
- Shift rate = (2/150) x 100% = 1.3 %
- Total Error rate = 11.3 + 1.3 + 1.3 = 13.9 %
The table below shows the statistics on the 133 landmarks that corresponded to EVA landmarks to within 100ms (i.e. all but the two shift errors).
Distance between Landmarks | EVA-to-Judge |
| Average | 19.2ms |
| Standard Deviation | 19.7ms |
| Median | 13.1 |
| Maximum | 86.5 |
Table 5: EVA vs. Human Comparison 2
EVA detected one +s/-s pair not found by the phonetician (judge); a second phonetician deemed that this pair was unclear. EVA omitted 19 landmarks labeled by the human judge. Of these, 12 landmarks (6 syllables) came from the 7-month recordings and represented syllables with substantial vocal fry; 4 landmarks (2 syllables) were found in a single digitized sample in a region of low vocal energy; the others may have been erroneous deletions by EVA. In all cases, the second phonetician concluded that the disagreements were within the bounds of typical inter-judge (human) differences.
8. CONCLUSIONS
We are optimistic, at this point, that EVA can validly and reliably find landmarks associated with infant syllable boundaries. This is the first step in establishing a method of automatically determining whether infant utterances are demonstrating the syllabic complexity to be expected at the end of the first year of life.
9. CURRENT AND FUTURE WORK
We are now using EVA to count the number and duration of syllables in all recordings of the five infants in this study. We are also noting the syllable patterns that EVA finds (e.g., +g/-g, +s/-s, +g/-s/-g) to see whether the distribution of these patterns changes over the five recordings for each infant.We plan to expand EVA to include categorization of syllables according to initial sounds (whether there is an initial consonant and if so, whether it is a stop, fricative, nasal, or liquid) and use this to develop an inventory of phones in infants' repertoires at each age level. The data will be used to establish an initial normative data base on the pre-speech development of typically developing infants.
10. ACKNOWLEDGMENTS
We would like to thank Sharlene Liu for making her code available to us, Ursula Muroff for recording the infants in this study, and Corine Bickley for her suggestions and her help as a third phonetician.This work was sponsored in part by NIH grant #R41-HD34686.
11. REFERENCES
[1] Bauer, H.R., 1988. Vowel Intrinsic Pitch in Infants, Folia Phoniatrica 1988, 40, 138-146.[2] Bayley, N. 1969. Manual for the Bayley scales of infant development. New York: The Psychological Corporation.
[3] Bickley, C. 1989. Acoustic evidence for the development of speech, RLE Technical Report No. 548, 111-124.
[4] de Boysson-Bardies, B., Halle, P., Sagart, L., and Durand, C., 1989. A crosslinguistic investigation of vowel formants in babbling. J. Child Lang., 16, 1-17.
[5] Capute, A. J., Palmer, F. B., Shapiro, B. K., Wachtel, R. C., & Accardo, P. J. 1981. Early lan-guage development: Clinical application of the language and auditory milestone scale. In R.E. Stark (Ed.), Language Behavior in Infancy and Early Childhood. New York.
[6] ESPS with Waves, 1993. Entropic Research Laboratory, Inc. AT&T Bell Laboratories
[7] Fell, H.J., Ferrier, L.J., Schneider, D., & Mooraj, Z. 1996, EVA, An early vocalization
analyzer: an empirical validity study of computer categorization. Proceedings of Assets '96, 57-61.
[9] Kent, R. D. & Murray, A. D. 1991. Acoustic features of infant vocalic utterances at 3, 6 and 9 months. In R. J. Baken & R. G. Daniloff (Eds.), Readings in Clinical Spectrography of Speech (pp. 402-414). New Jersey: Singular Publishing Group and Kay Elemetrics.
[10] Kent, R. D. & Read, C. 1992. The Acoustic Analysis of Speech, San Diego: Singular Publishing Group, Inc.
[11] Liu, S. 1994. Landmark detection of distinctive feature-based speech recognition. Journal of the Acoustical Society of America, 96, 5, Part 2, 3227.
[12] Liu, S. 1995. Landmark Detection for Distinctive Feature-based Speech Recognition. Ph.D. Thesis. CamPidge, MA: Mass. Inst. Tech.
[13] Locke, J. L. 1989. Babbling and early speech: Continuity and individual differences. First Language, 9, 191-206.
[14] Locke, J. L. 1993. The child's path to spoken language. CamPidge, MA: Harvard Univ. Press.
[15] Menyuk, P., Liebergott, J., Shultz, M., Chesnick, M, & Ferrier, L.J. 1991. Patterns of Early Language Development in Premature and Full Term Infants. J. Speech and Hearing Res. 34, 1.
[16] Menyuk, P., Liebergott, J., & Shultz, M. 1995. Early Patterns of Language Development in Full Term and Premature Infants. Lawrence Erlbaum Associates: Hillsdale, N.J.
[17] Oller, D.K. 1980. The emergence of sounds of speech in infancy. In G. H. Yeni-Komshian, J.F. Kavanagh, & C.A. Ferguson (eds.), Child Phonology Volume 1: Production . New York: Academic Press.
[18] Oller, D.K. & Lynch, M.P. 1992. Infant utterances and innovations in infraphonology: Toward a Poader theory of development and disorders. In Ferguson, C.A., Menn, L., & Stoel-Gammon, C. (Eds.), Phonological Development: Models research implications (pp. 509-536). Timonium, Maryland: York Press.
[19] Oller, D. K. & Seibert, J. M. 1988. Babbling of prelinguistic mentally retarded children. American Journal on Mental Retardation, 92, 369-375.
[20] Proctor, A. 1989. Stages of normal noncry vocal development in infancy: A protocol for assessment. Topics in Language Disorders, 10 (1), 26-42
[21] Stark, R.E. 1981. Stages of Development in the first year of life, In Child Phonology: Vol. I, G. H. Yeni-Komshian, C. A. Ferguson, J. Kavanagh (Eds.), New York: Academic Press.
[22] Stevens, K.N. 1992. Lexical access from features. Speech Communication Group Working Papers, Volume VIII, Research Laboratory of Electronics, MIT, 119-144.
[23] Stevens, K.N., Manuel, S., Shattuck-Hufnagel and Liu, S. 1992. Implementation of a model for lexical access based on features. Proc. Int'l. Conf. Spoken Language Processing, Banff, Alberta, 1, 499-502.
Copyright Notice
The works here are copyright by the Association for Computing Machinery, Inc. (ACM) and by the respective authors. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that the copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior spcific permission and/or a fee. For more information please e-mail: permissions@acm.orgPosted by:
Harriet Fell
College of Computer Science, Northeastern University
360 Huntington Avenue #161CN,
Boston, MA 02115
Internet: fell@ccs.neu.edu
Phone: (617) 373-2198 / Fax: (617) 373-5121
Last Updated: April 12, 1998 7:50 pm
The URL for this document is:
http://www.ccs.neu.edu/home/fell/fellAssets98.html